Azure Data Fundamentals過去問を解いて作った勉強法【DP900】
- 2024.07.28
- Azure

この記事では、Azure Data Fundamentals(DP900)を受験し、合格した際の勉強方法を紹介します。
DP900の難易度
合格までに要する時間は毎日1時間試験対策して、1か月は必要だと思います。私の場合は一度不合格になったりしたため、3か月程度要しました。
混同しやすいAzure用語
Azureには非常に多くのサービスが存在し、それぞれが異なる機能を提供しますが、名前が似通っています。例えば、大量のデータを保存するためのストレージサービスですが、同じ「ストレージ」というカテゴリには「Azure Files」や「Azure Storage」なども存在し、それぞれの用途が異なります。
申し込みの流れと受験方法
Microsoftの公式サイトにアクセス
試験の申し込みは、Microsoftの公式試験プロバイダーであるPearson VUEのウェブサイトから行います。以下の手順で申し込みができます:
- Microsoft認定試験のページにアクセス: Microsoftの認定試験ページにアクセスし、Azure Data Fundamentals(DP-900)の試験情報を探します。
- Pearson VUEのアカウントを作成: Pearson VUEのウェブサイトにアクセスし、アカウントを作成します。すでにアカウントを持っている場合は、ログインします。
- 試験の予約: Pearson VUEのサイトで「試験を予約」セクションに進み、DP-900を選択します。試験の受験場所や日時を選びます。試験はオンラインで自宅から受験することもできますが、指定のテストセンターでの受験も可能です。
- 試験料の支払い: 試験の受験には料金がかかります。支払い方法を選び、料金を支払います。
- 確認と準備: 申し込みが完了すると、試験の確認メールが届きます。受験前に必要な準備やチェックリストも確認しておきましょう。
試験の形式
- 試験時間:約60分。
- 問題形式:選択式、ドラッグアンドドロップ、リスト形式など。
試験の実施
- オンライン受験:自宅で受験する場合、受験環境(カメラ、マイク、PCの設定など)が適切であることを確認する必要があります。試験中は監視が行われるため、適切な受験環境を整えましょう。
- テストセンターでの受験:指定された試験センターで受験します。試験センターには、試験の開始時間の少なくとも30分前に到着するようにしましょう。
試験の結果
試験が終了すると、試験結果がすぐに表示されます。合格した場合は、Microsoftからデジタルバッジや証明書が送られます。不合格の場合は、再試験の予約が可能です。
有効期限
Azure Data Fundamentalsの資格は、取得後から2年間有効です。資格の有効期限が近づくと、Microsoftから更新の案内が届くことがありますが、自分でも更新のタイミングを確認しておくと良いでしょう。
実際の勉強方法と参考書
- Microsoft Learnの試験準備コースを読む
まずは、Microsoft Azureのデータの基礎のモジュールを一通り読み、要点をGoogle SpreadSheetにまとめました。また、このモジュールはGoogleアプリのSpeak Aloud機能で再生できたので、通勤・散歩中のながら学習に便利でした。このコースの内容を覚えれば合格できるのですが、全体的に翻訳調で読みづらかったです。 - Microsoft Learnの練習問題を解く
練習問題を繰り返し解き、上記のSheetに正答できなかった問題を解くために必要な知識を追記していきました。これを合格ラインの80%の正答率が繰り返し取れるようになるまで続けました。 - Udemyの練習問題を解く
下記のUdemyの練習問題を解き、誤った問題の正答を上記のGoogle SpreadSheetに記録し、繰り返すことで無事合格できました。
・DP-900 Azure Data Fundamentals 模擬問題集
・DP-900: Azure Data Fundamentals | DP900 Practice Tests
コースを選ぶ際には以下の点に注意しましょう:
- 試験内容に準拠したコース: DP-900試験の公式ガイドや試験範囲に準拠したコースを選びましょう。
- レビューと評価: 他の受講生のレビューや評価を確認し、高評価のコースを選びます。
- 最新情報の反映: Azureは頻繁に更新されるため、最新の情報が含まれているコースを選びます。
過去問を解いて作った勉強法
データの基本概念
構造化データ、半構造化データ、非構造化データの違いと、それぞれに関連するファイル形式について理解することが必要です。
1. 構造化データ
構造化データとは、行と列で構成されたテーブル形式のデータです。
- 例: 顧客情報を管理するテーブル(顧客ID、名前、住所、電話番号など)
2. 半構造化データ
半構造化データは、構造化データと非構造化データの中間に位置するデータ形式です。データ全体が厳密なスキーマに従っていないものの、一部に規則的な構造を持っています。このため、柔軟性が高く、さまざまなデータを扱うことが可能です。代表的な形式には以下のものがあります。
- CSV(Comma Separated Values): データをカンマで区切って記述したテキストファイル形式。簡易で扱いやすい。
- JSON(JavaScript Object Notation): データをキーと値のペアで表す軽量なデータ交換形式。APIやWebアプリケーションで広く使用されている。
- XML(Extensible Markup Language): 階層構造を持つデータ形式で、タグを使ってデータを記述します。データの階層構造を表現するのに適しており、構造を柔軟に定義できる。
3. 非構造化データ
非構造化データとは、明確な構造を持たないデータです。このデータ形式はリレーショナルデータベースで直接管理するのが難しく、大規模なストレージや高度な分析処理が必要です。
- 例: 動画ファイルや音声ファイル、写真などのメディアコンテンツ
リレーショナルデータの取り扱い考慮事項
ここでは、正規化とSQLの基礎について解説します。これらはデータベース設計および操作において重要な概念であり、試験にも頻出です。
正規化は、データベース内のデータを整理し、冗長性を減らし、データの整合性を高めるプロセスです。データが不適切に整理されていると、同じデータを複数箇所で管理する必要が出てきたり、データの不整合が発生しやすくなります。以下のステップを踏むことで、データを効率的に正規化することができます。
正規化のプロセス
- 各エンティティを独自のテーブルに分離
例: 顧客情報、注文情報、製品情報など、異なる概念(エンティティ)ごとにテーブルを分けます。 - 個別の属性を独自の列に分離
各エンティティの属性(顧客名、注文日、製品名など)を、それぞれ独自の列として整理します。 - 主キーを使用して各エンティティインスタンスを一意に識別
主キー(例: 顧客ID、注文ID)は、各行を一意に識別するために使用されます。 - 外部キー列を使用して関連エンティティをリンク
異なるテーブル間の関連を作成するため、外部キー(例: 顧客IDと注文テーブル)を利用して、テーブル同士をリンクします。
正規化する理由
- データの冗長性が減少
データが重複するリスクが減り、データベースの容量を節約できます。 - データの整合性を向上させる
データが一元管理され、矛盾が生じにくくなります。 - 更新、挿入、削除の最適化
データの変更時に他の場所で矛盾が生じにくく、効率的に操作を行えます。
SQL(Structured Query Language)は、データベースを操作するための言語です。SQLには、データ定義言語(DDL)、データ制御言語(DCL)、データ操作言語(DML)の3つの主要なカテゴリがあります。
データ記述言語(DDL)
DDLは、データベース内のテーブルやその他のオブジェクト(テーブル、ストアドプロシージャ、ビューなど)の作成や変更、削除を行うために使用されます。
- 主なコマンド:
CREATE,ALTER,DROP,RENAME
データ制御言語(DCL)
DCLは、特定のユーザーまたはグループに対するアクセス権を管理するために使用されます。
- 主なコマンド:
GRANT,DENY,REVOKE
データ操作言語(DML)
DMLは、データの取得や挿入、更新、削除など、実際のデータ操作を行うために使用されます。
- 主なコマンド:
SELECT,INSERT,UPDATE,DELETE,MERGE
一般的なデータベースオブジェクト
- クラスタードインデックス
クラスタードインデックスは、キー値に基づいてテーブルの行をソートおよび格納するオブジェクトです。これにより、データの検索や取得が高速化されます。 - ビュー
ビューは、クエリを基に定義される仮想テーブルです。実際のデータは保持していないため、データの簡易的な表示やアクセス制御に使用されます。 - ストアドプロシージャ
ストアドプロシージャは、複数のSQLコマンドをまとめて保存し、後から簡単に実行できるようにするためのプログラムです。例として、以下のコードは製品名を変更するストアドプロシージャです。
リレーショナルデータベースは、構造化データを格納し、クエリ言語としてSQL(Structured Query Language)を使用するデータベース管理システムです。このデータベースは、データが行と列で構成されたテーブルに格納され、データの関係性を明確に管理するために使用されます。一般的には、金融システムや在庫管理など、データの一貫性や正確性が重視されるアプリケーションに適しています。
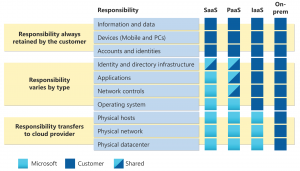
Azureはリレーショナルデータベースのさまざまなサービスを提供しています。それぞれのサービスは、異なるユースケースや管理レベルに合わせて選択可能で、PaaSやIaaSの形で利用できます。詳細は下記を参照ください。
非リレーショナルデータの取り扱い考慮事項
非リレーショナルデータベースは、リレーショナルスキーマを適用しないデータベース管理システムです。従来のテーブル形式に縛られないため、データの構造が多様であるケースや、データ量が非常に多い場合に適しています。これにより、柔軟かつスケーラブルなデータ処理が可能になります。
非リレーショナル データを格納するために使用されるAzure Storageについては下記を参照ください。
分析ワークロード
Azure Data Fundamentalsの試験では、データ処理アーキテクチャの理解が重要です。この記事では、データの取り込み、処理、保存、分析、および視覚化の各段階について、Azureのサービスを活用したアプローチを解説します。
1. データの取り込み (Data Ingestion)
データ取り込みは、データをシステムに取り入れるプロセスで、ストリーミングデータとバッチデータの2種類があります。Azureでは、データ統合やETLパイプラインの実行にAzure Data Factoryがよく使われます。
ETLプロセス(Extract, Transform, Load)
ETLは、生データを抽出し、保存前に変換し、ロードするプロセスです。
- ETLを行う理由:
- 機密データの転送頻度を減らす。
- ソースシステムに依存しない計算リソースを使用してデータを変換する。
- 大量のデータを効率的に転送するため、転送時間を最小限に抑える。
ELTプロセス(Extract, Load, Transform)
ELTは、データをまず取り込み、その後に変換を行います。特に大規模で複雑なデータモデリングが必要な場合や、データレイクやウェアハウスにデータをロードする場合に使われます。
データ取り込みのためのAzureサービス
- Azure Data Factory: 異なるデータソースからデータを取得し、処理するためのETLサービス。
- Azure Stream Analytics: リアルタイムデータ処理に使用され、データストリームを集約し、データレイクに書き込む前に処理を行います。
2. データ処理 (Data Processing)
データの処理は、取り込んだ生データを意味のあるデータ形式に変換するプロセスです。データをテーブル形式に変換したり、グラフやドキュメントとして視覚化することが含まれます。Azureのデータ処理には以下のサービスが活用されます。
- Azure Databricks: Apache Sparkをベースにした処理エンジンを持ち、大量データの分散処理に適しています。Azure SQL DatabaseやAzure Cosmos DBとも統合可能です。
- Azure HDInsight: Hadoopベースのデータ処理に使用され、スケーラブルなデータ処理が可能です。
3. 分析データ ストア (Analytical Data Store)
データの保存には、データレイクやデータウェアハウス、そしてデータレイクハウスといった異なるアーキテクチャが利用されます。これらはそれぞれ、異なるタイプの分析に適しています。
データレイク
- 構造化、半構造化、非構造化データをファイル形式で格納します。スケーラブルで、主に生データの格納に使われます。
データウェアハウス
- 構造化データを格納し、データを効率的にクエリするためにスターやスノーフレークスキーマを利用します。
データレイクハウス
- データレイクに表形式の抽象化を追加し、データウェアハウスと同様のクエリを可能にするアーキテクチャ。Sparkベースであり、リアルタイム分析にも適しています。
分析ストアのためのAzureサービス
- Azure Synapse Analytics: 超並列処理(MPP)によって大量データの処理が可能で、データレイクとSparkの柔軟性を組み合わせることができる。
- Azure Databricks: Apache Sparkを使用してデータを高速に処理し、複数のクラウドプロバイダーをサポートしています。
4. 分析データ モデル (Analytical Data Model)
データモデルの設計は、データ分析の効率を左右します。特に、OLAP(Online Analytical Processing)モデルは、データを多次元的に集計し、複雑なクエリを高速に実行するために使用されます。
5. データの視覚化 (Data Visualization)
データ処理後、データを視覚的に表現することは、意思決定に不可欠です。Power BIは、データを直感的に表示し、分析結果をダッシュボードやレポートとして提供するためのツールです。
Power BIの主な機能
- Power BI Desktop: ローカル環境でレポート作成を行うためのツール。
- Power BIサービス: クラウドベースでレポートやダッシュボードを共有し、共同作業を行うためのプラットフォーム。
-
前の記事

Azure Storageの種類(Blob, File)を比較 2024.07.01
-
次の記事
記事がありません
